Concurrency in Python
23-05-20262087 words11 min read
Introduction
A server's operations can be broadly divided into two types.
- One, receiving and sending data
- Two, running business logic on the data
The reason we talk about input and output in the same breath is because an output is almost always followed by a wait for input. In any server you create, IO happens at multiple points. Let's consider an API server which exposes a GET endpoint, for facilitating the retrieval of user information. From the server's perspective, I/O will happen at least at 3 points:
- Inbound Network IO: The api request sent by the user hits the network card and travels to the Python runtime via OS buffer.
- DB IO/ Disk IO: Once recieved, the endpoint handler either makes a query to the database or reads data from a disk.
- Outbound Network IO: Once data from the storage unit is retrieved, the python runtime curates a json object, wraps it up in the response payload and sends it to the Kernel which directs it to the network card. From there it is sent back to the user browser.
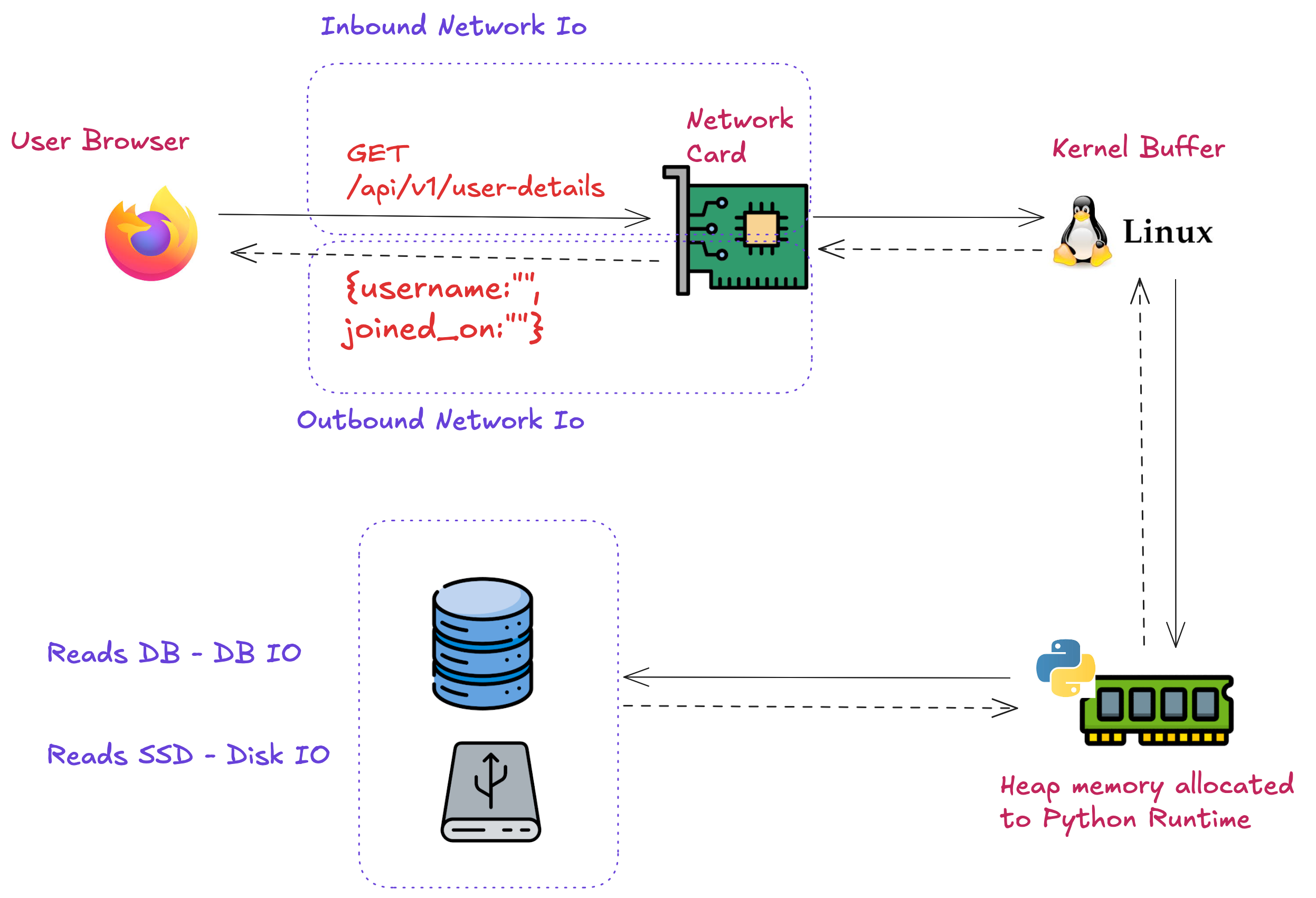
Now imagine an API server built for an e-commerce platform. It will have a hundred endpoints if not more and a lot of internal/ external services(present on another server) will be used. In that case, you as a developer will be needed to implement a system that efficiently manages all points of IO so the server doesn't have to wait long for the data it needs to serve its user, or in other words, you have to ensure that IO doesn't become a performance bottleneck for the whole system. After all, it's just a cog in the ginormous wheel which is your server.
Forms of IO
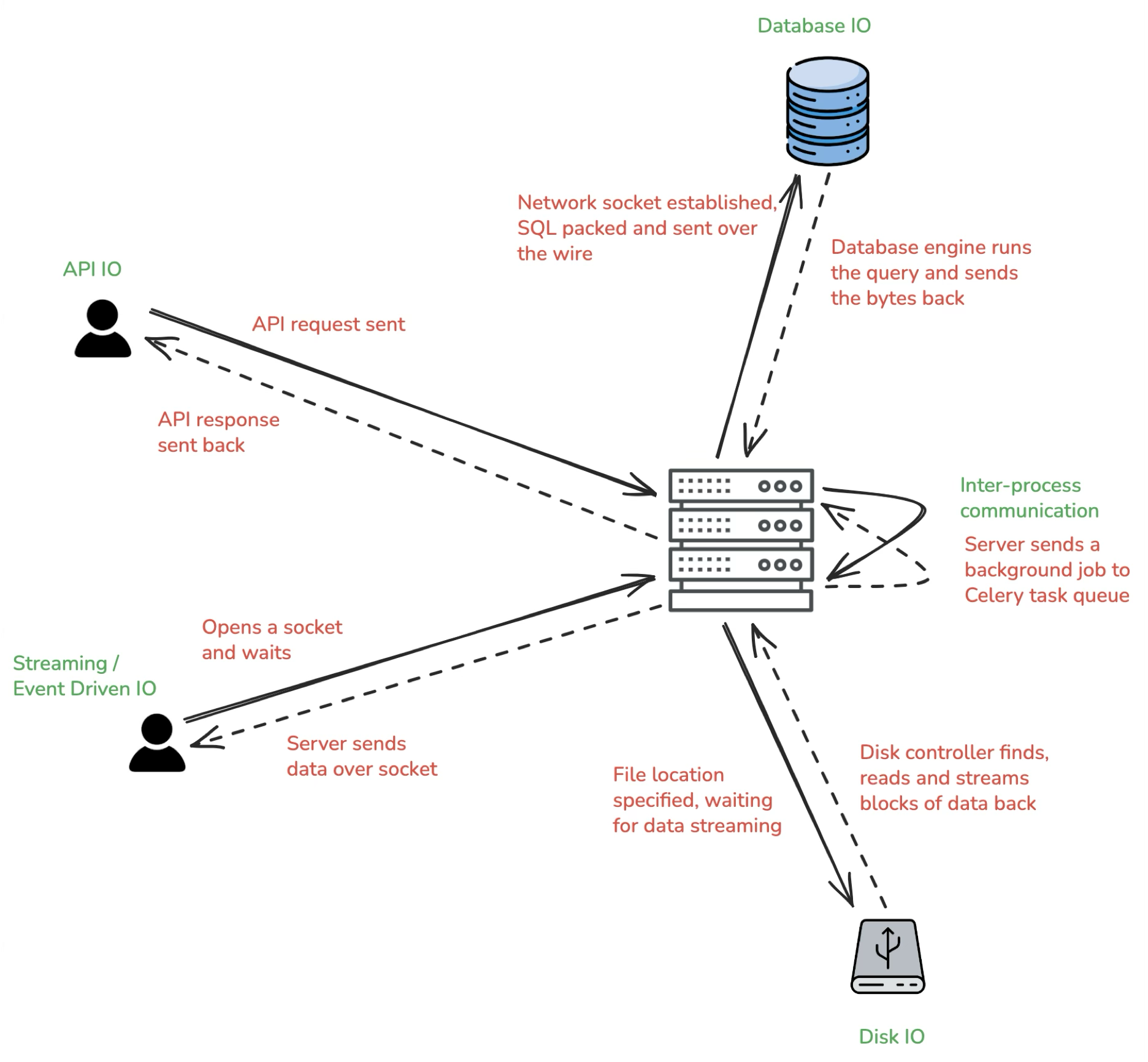
Need for IO arises out of the fact that modern web servers are stateless, meaning they rely on seperate/external systems to build their state and do work. A few examples of the same are:
- Network IO: A server getting an HTTP request from a user browser and sending back a repsonse in the same direction
- Streaming IO: A server establishing a websocket channel with a user or a broadcasting channel among multiple users and then the participants can exchange messages for as long as they want
- Disk IO: A server might need to read a file stored on its disk or maybe you have used bulk storages such as AWS S3 or Azure Blob Storage both of which are deployed on verdor servers
- Database IO: Depending on the client's request, server may need to write an sql query to a databse which just like the disk, could either be present on the server (a locally running postgres/mysql/sqlite/mongodb instance) or something provided by one of the cloud vendors.
- Inter-process Communication: Sometimes, the python runtime has to communicate with processes other than itself such as task queues(Celery), message brokers(Redis) etc. The OS Kernel runs them on their own threads. So any message sent between them has to travek through multiple layers before reaching its destination.
The common denominator in all of these forms of communication is, the server will inevitably have to wait for data to come from them. But the question that matters is, how long can the server afford to wait, turns out, not long enough. After all, user experience will suffer and failures will occur at multiple layers(Browser timeout, Load Balancer timeout, thread blocked etc), effectively stranding the whole app for every single user. Bad stuff. And in a single threaded world it woukd be the reality, were it not for The Event Loop.
Types of Multitasking
Multitasking is divided into 3 types Multiprocessing, Multithreading, Asyncio. Within this list, the first two fall under the categoy of prememptive multitasking and the last one under cooperative multitasking. Python provides libraries to accomplish all three, namely, ProcessPoolExecutor, ThreadPoolExecutor and asyncio, respectively.
Why discuss this topic you ask? Because its easy to mix up their features and get confused about why we make a distinction between them at all. But more than that, I need to help you draw a mental model on the heirarchical differeces that exists between these three, so I can establish the importance of Asyncio to Python over the other two.
Multiprocessing
Modern computers range anywhere from having 4 to 16 core CPUs. So when the OS Kernel spins up a different process on each core and gives it exclusive access to a part of memory, CPU and Kernel resources, thats when we say multiprocessing is in place. On one hand this is a way to achieve true parallelism (because different processes are executing simultaneously) and fault isolation(processes don't interfere with each other) but it is very resource exhaustive. In addition to the resource allocation at startup time processes must use Inter-Process Communication (IPC) mechanism to talk to other processes, thus adding another layer of complexity.
Multithreading
Imagine multiple clones of a process running on the same core, along with the main process. These clones are threads and this is called multithreading. All threads have access to the same heap memory but unlike multiprocessing, there is no mechanism to run them truley parallely, instead they must be run sequentially. But even this sequential execution occurs so fast that it can be mistaken for parallelism. This is accomplished by the OS Kernel through context switching which involves saving the context of current thread (program counter, CPU registers' content and the thread stack) in the Thread Control Block(in kernel space), letting another thread lock onto resouces and getting its work done, then reviving the suspended thread to complete its remaining task. The overhead of context switching alone is enough to present multithreading as an unsavooury option. Moreover, a crash in one thread can corrupt the entire process.
Asyncio
Now if we go a step further, and divide a thread into multiple tasks, that changes a lot of things. Suddenly, the Kernel doesn't need to prepare an isolated environment or worry about context switching. In fact the responsibility to manage tasks is shouldered by the python runtime. Asyncio enables the user to mark the code blocks that need to pause and wait for data to come from elsewhere which is very special because when execution reaches that block, it voluntarily relinquishes control to the orchestrator (The Event Loop) and waits. When its data arrives, the Event Loop wakes it up (metaphorically). So, it is deterministic(no preemption), causes way less overhead(the task only needs to remember what line of code it was executing along with the variable values before pausing), doesn't require complex code(unlike multithreading where Memory Access Synchronisation has to be performed via constructs like locks, semaphores etc). But asyncio is not bulletproof either, if an expensive code block is made synchronous, it will choke the whole app.
The evolution of Concurrency Engine
How did concurrency primitives take the form that we are so faimiliar with today? Did the Async-await syntax and the event loop exist since the beginning or was there a gradual evolution that took foundational and (initially) unrelated concepts there?
It all began with the introduction of Global Interpretor Lock(GIL) in Python 1.5. It is the phenomenon which made python interpreter thread safe and simple but also single threaded. At its core, the GIL is a mutex which ensures that only one thread can execute the python bytecode at any given moment in time. It was adopted for multiple reasons such as multicore CPUs being a rairity in that era (1990s), the ease of development with CPython extensions. Although Python still supports multi-threading but asyncio is the more suggested and popular paradigm out there, because Python is much slower than the other alternatives (Go, Rust, Java, C++, C#, etc). The slow speed is inherently caused by GIL's enforecement of the only one thread executes python at a time policy.
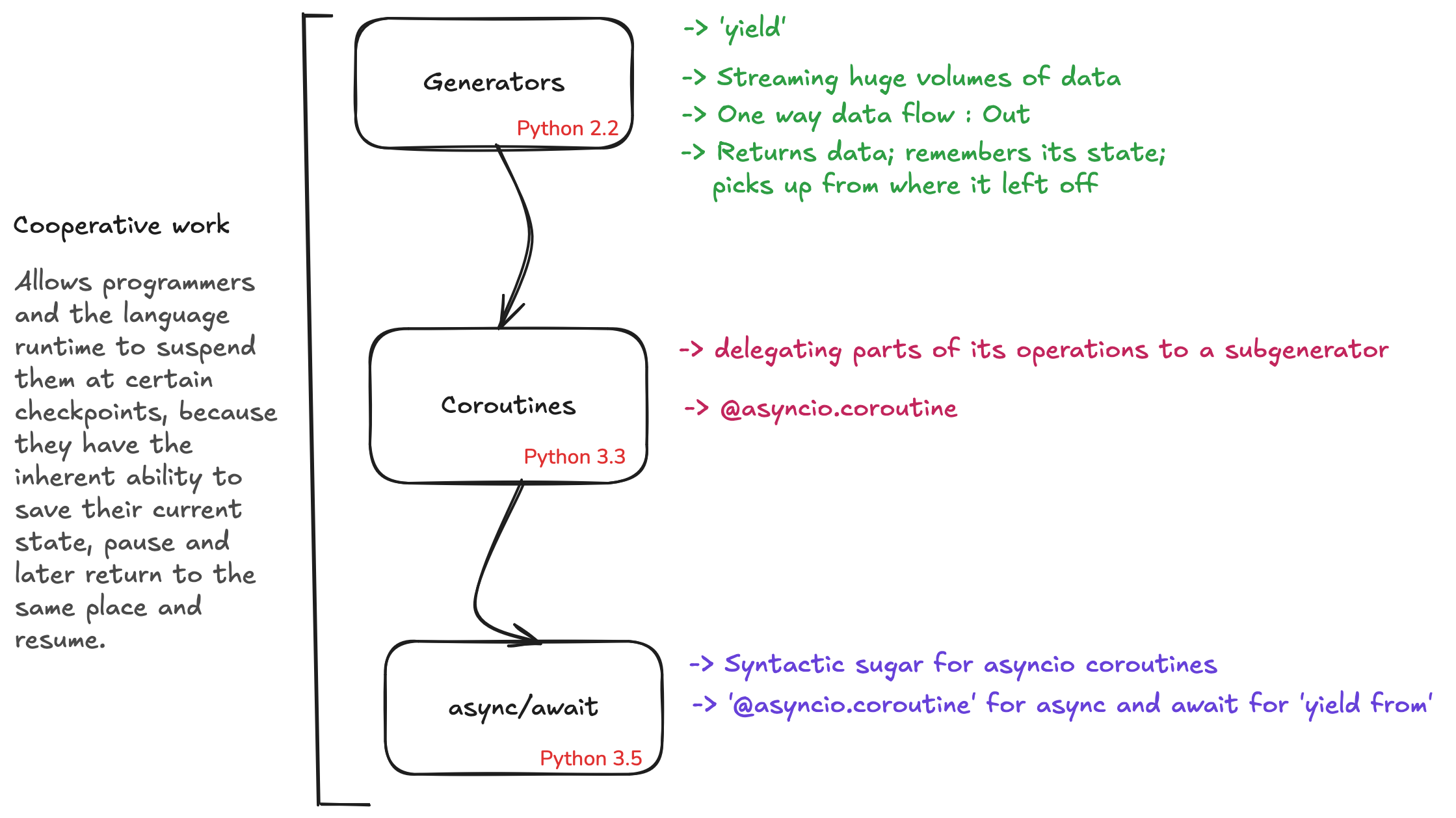
From then till the introduction of the event loop, python developers used a number of techniques to get concurrent tasks done, but they were all highly inefficient. But after a few breakthroughs like generator functions, OS notification systems(kqueue) and the O_NONBLOCK flag, the event loop was brought into existence in Python 3.3, which proved to be a gamechanger. Over time it was refined and in Python 3.5 async-await was introduced, which got established as the de-facto way of concurrent programming in Python.
Generators
An unrelated development happened with the release of Python 2.2, generator functions were introduced. Equipped with the ability to pause and resume later where they left off, they proved to be a great solution for streaming data. The syntax looked pretty much like standard functions, except, 'return' keyword was replaced by 'yield' and since it produced output in chunks, the 'next()' method was used to trigger output of the next chunk.
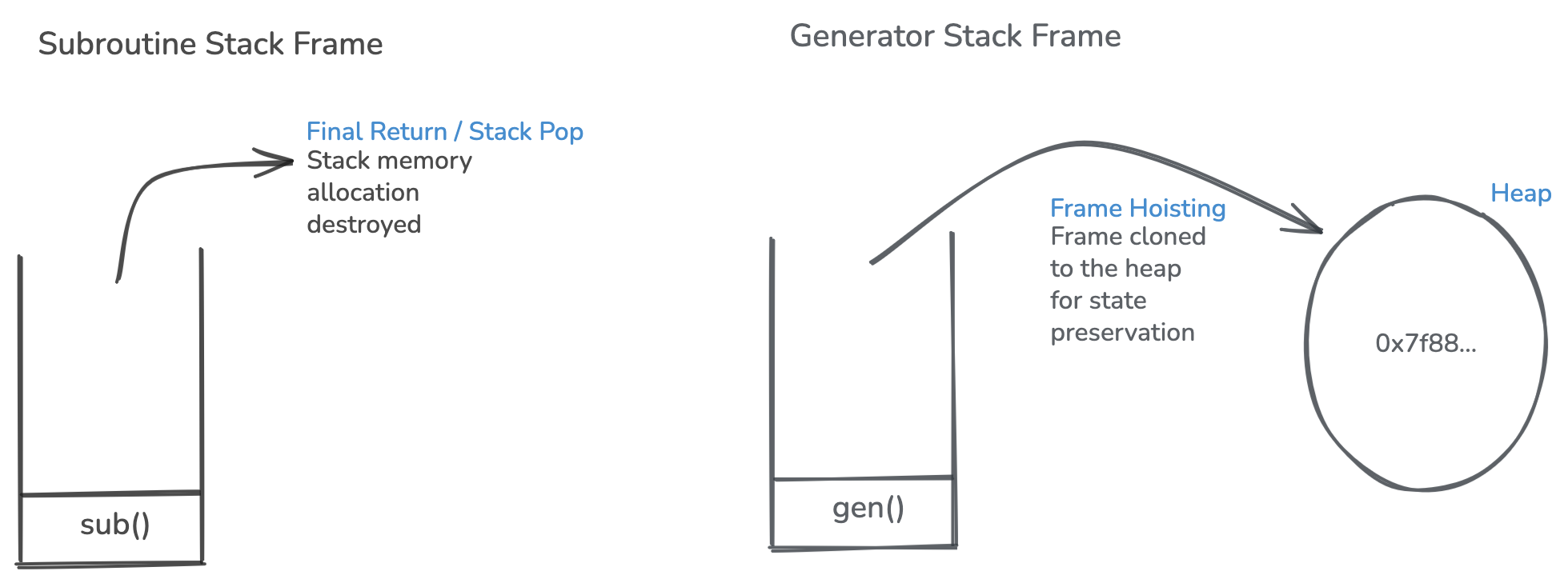
In technical terms, standard functions are called subroutines. The diagram above demonstrates how a subroutine's execution differs from that of a Generator function's. Hitting a return statement completes a subroutine's execution and pops it from the call stack. In contrast, as soon as a generator function hits a yield statement, stores reference to the line it was executing and the variables it was using in the heap memory, entering paused state.
Coroutines
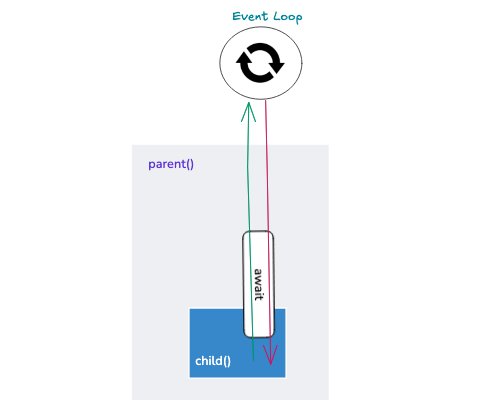
With the advent of O_NONBLOCK flag and kqueue, the python team noticed that they could use generator functions' ability of pausing, to wait for IO. But who'll wake up the generator function upon the data's arrival? How about an orchestrator that acts as a middleman between kqueue and the function, so that, when data arrives at the network card, kqueue notifies the event loop which wakes up the function and tells it to continnue its execution from where it left off. The syntax adopted involved two changes:
- 'yield from' statement was capable of calling coroutines(and subroutines). It acted as a pipe for direct communication between the event loop and the coroutine being called.
- '@asyncio.coroutine' decorator was used to mark a function as an IO requiring task for the event loop.
Async/await
async-await terminology is essentially syntactic sugar for the coroutine syntax. It is much easier to use and understand than a conjunction of 'yield from' and '@asyncio.coroutine' which can be easily confused with generator syntax.
The Event Loop
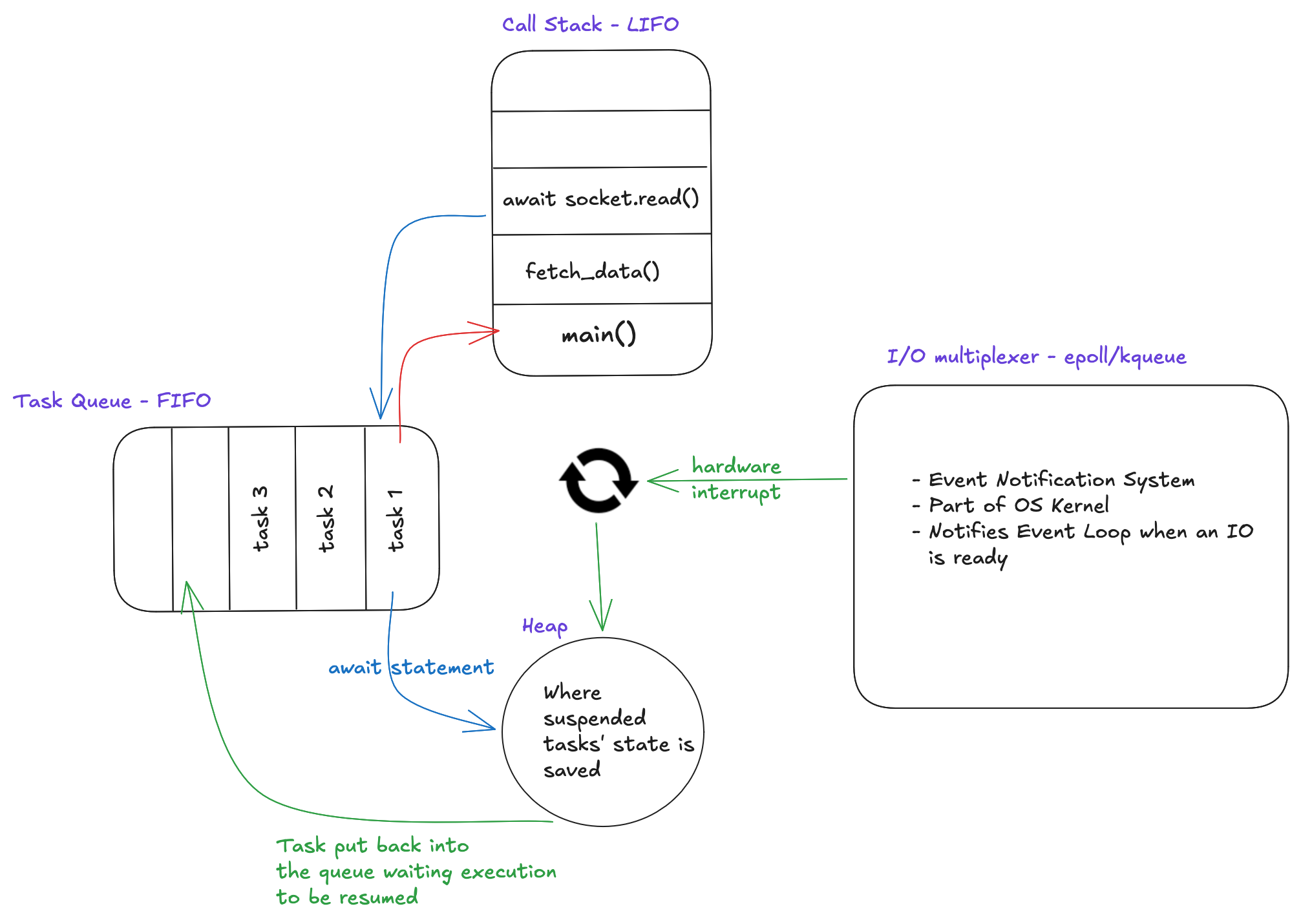
The Event Loop is the main man in the modern concurrency architecture. It controls tasks which need to wait for IO. The main components which encapsulate its functionality are the Call Stack, Task Queue, Heap Memory and the IO multiplexing mechanisms. Here is a brief explanation of all of them:
- Task Queue: It is a data structure which operates on the principle of First In First Out(FIFO) and is used to store async tasks.
- Call Stack: As the name suggests it is a stack (operating on Last In First Out principle) data structure, used to keep track of which code block is being executed. Each frame of the Call Stack is devoted to executing one function call. When that call happens to be marked by an await keyword, the Event Loop clears out the whole stack and informs the IO Multiplexer to do its job and look out for the data this coroutine needs.
- Heap: This is the memory provided to the event loop everytime a python process is started. When the Event loop suspends an async task, it saves its state here.
- IO Multiplexing Mechanism: kqueue is used to keep tabs on the IO sockets. Once the data arrives, it informs the Event Loop via hardware interrupts which puts the task back into the Task Queue, where it waits its turn on the Call Stack.
Never block the loop
As I said before, async-await is not bullet proof. One of the loopholes is that, the presence of synchronous code can choke the event loop. After all, the event loop is single threaded. Violations of this constraint can be performed in a number of ways, such as:
- Using time.sleep() function, for loops or (synchronous) sql queries
- Sometimes you cannot avoid using old libraries that are not compatible with the asynchronous paradigm, such as, requests and psycopg2
- Computation heavy tasks like image processing or math can also be quite heavy
In case the synchronous task cannot be avoided, it is suggested to use either ThreadPoolExecutor(I/O Bound, creates a pool of threads) or ProcessPoolExecutor(CPU Bound, creates a pool of processes).